4. Behältervariablen und Umgebungsmodell
Wenn Zuweisungen an Variablen erlaubt sind, ist eine Variable nicht mehr der Name für ihren Wert, sondern beschreibt einen „Ort“, an dem Werte gespeichert werden können (Behältervariablen). Da Variablennamen mehrfach benutzt werden können, werden die Orte in Umgebungen verteilt. Das Verhalten von Behältervariablen läßt sich nicht mit dem einfachen Substitutionsmodell[1] beschreiben. Daher muß es zum Umgebungsmodell erweitert werden.
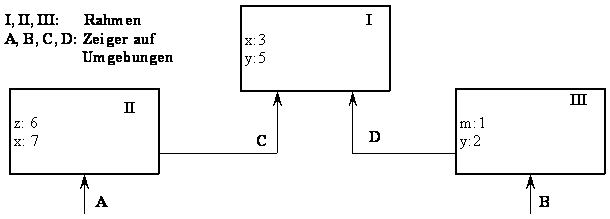
Eine Umgebung ist eine Folge von (Bindungs)Rahmen. Jeder Rahmen ist eine
eventuell leere Tabelle von Bindungen, die den Variablen zugehörige Werte
zuordnen. Jeder Rahmen enthält auch Zeiger auf die zugehörige Umgebung, außer
beim globalen Rahmen. Der Wert einer Variablen bezüglich einer Umgebung ist der
Wert in dem ersten Rahmen, die überhaupt eine Bindung für die Variable enthält,
sonst ist die Variable ungebungen.
Bsp.: Umgebung A: Die Bindung von x=7 im Rahmen II überschattet die Bindung von x=3 im Rahmen I.
Die Umgebung spielt eine entscheidende Rolle bei der Auswertung, da sie den Kontext bestimmt, in dem der Ausdruck ausgewertet wird. Ausdrücke für sich haben – anders als im Substitutionsmodell – kein (vollständige) Bedeutung. Selbst ein Ausdruck wie (+ 1 1) hat nur Bedeutung, wenn + in der Umgebung das Symbol für die Addition ist.
Auswertungsregeln
Zur Auswertung von Kombinationen (außer Sonderformen)
1. Werte Teilausdrücke der Kombination aus (Achtung: Reihenfolgeproblematik)
2. Wende den Wert des Operators auf die Werte der Operanden an.
Neu: Bedeutung der Anwendung einer Prozedur auf die Argumente:
Im Umgebungsmodell ist eine Prozedur immer ein Paar, das aus Code und einem Zeiger auf die Umgebung besteht.
Bsp.: int quadrat (int x) {return x * x;}
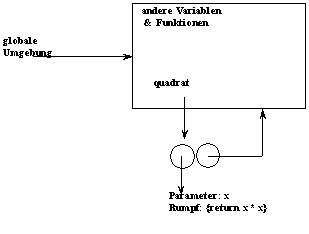
Zur Anwendung einer Prozedur auf ihre Argumente erzeuge eine neue Umgebung mit einem Rahmen, in dem die Parameter an die aktuellen Werte der Argumente gebunden sind. Der neue Rahmen zeigt auf die Umgebung, in dem die Prozedur definiert ist.
(wenn in der globalen Umgebung auch eine Variable x vorkommt, dann ist sie in E1 überschattet).
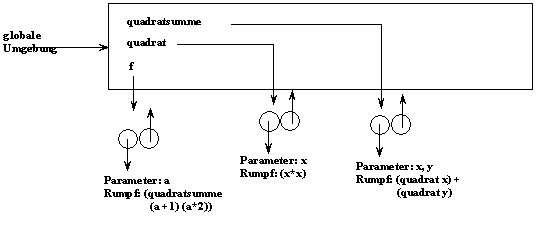
Auswertung einfacher Prozeduren
Wdh.: (f 5)
1. Funktionsdefinitionen:
2. Bei der Auswertung von (f 5) werden folgende Umgebungen E1-E4 erzeugt:
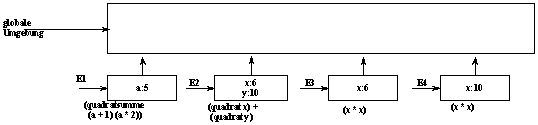
Die Zuweisung „=“ ändert den Wert einer Variablen in einer Bindungsumgebung.
public class konto {float
kontostand; konto (float n) {kontostand = n;}
public boolean abheben (float betrag)
{if (kontostand >= betrag) {kontostand =
kontostand – betrag; return true;} else return false;}}
konto w1 = new konto (100);
konto w2 = new konto (200);
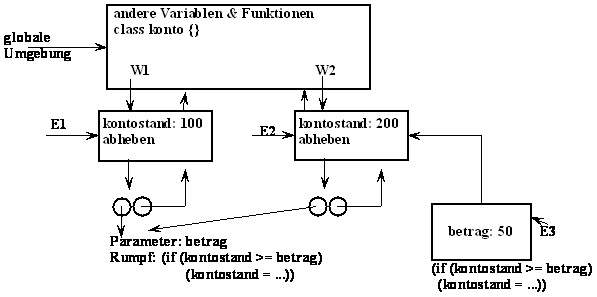
w2.abheben (50);
Das Umgebungsmodell erklärt die beiden nützlichen Eigenschaften von lokalen Prozedurdefinitionen:
1. Die Namen der lokalen Prozedure überschneiden sich nicht mit Namen außerhalb der sie umgebenden Prozedur.
2. Die lokalen Prozeduren können auf Argumente der umgebenden Prozedur zugreifen.
Modelle mit veränderbaren Daten
5.
Objektorientierung
5.1 Externe
Qualitätsanforderungen an Software
1. Korrektheit: Übereinstimmung
mit Spezifikation
2.
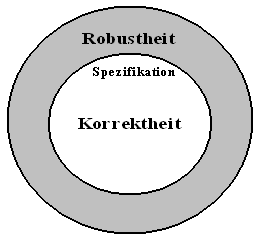
Robustheit:
Funktionsfähigkeit auch unter abnormen Bedingungen
3. Erweiterbarkeit:
Anpassungsfähigkeit an Änderungen der Spezifikation
4. Wiederverwendbarkeit:
Benutzbarkeit von Software(teilen) in anderen Programmen
5.
Kompatibilität: Kombinationsfähigkeit eines Programmes mit anderen
6. Effizienz
7. Portabilität:
Anpassungsaufwand für andere Hard- und Softwareumgebungen
8. Validierbarkeit: Einfachheit
der Validierung
9. Integrität: Schutz vor nicht
berechtigtem Zugriff und Änderung
10.
Bedienbarkeit: Einarbeitungs- und Bedienzeit
(1-5
profitieren von OOP; 6-10 kaum)
5.2 Fünf
Kriterien zur Modularität[2]
-

Modulare Zerlegbarkeit: Die Module können
unabhängig voneinander entwickelt werden, sofern die Schnittstellen eingehalten
werden. Bsp.: Top-Down-Design; Gegenbeispiel: Initialisierungsmodul
-

Modulare Zusammensetzbarkeit: Module können leicht
zusammengesetzt werden. Bsp1.: Unterprogramm-Bibliotheken. Bsp2.: UNIX-Shell-Konventionen
A|B. Gegenbeispiel: Preprocessors (z.B. für Grafik und für Kontrollstrukturen)
-
Modulare Verständlichkeit: Ein Modul sollte aus sich
selbst heraus verständlich sein (höchstens unter Einbezug einiger
Nachbarmodule). Gegenbeispiel: Sequentielle Abhängigkeiten
-
Modulare Kontinuität: Kleine Änderungen sollten
auch nur kleine Auswirkungen haben und nur wenige Module betreffen,
insbesondere nicht die Aufteilung in Module selbst in Frage stellen. Bsp1.:
Symbolische Konstanten. Bsp2.: Uniforme Referenz auf Daten und Funktionen (z.B.
Alter). Gegenbeispiel: Statische Arrays mit festen Grenzen.
-
Modularer Schutz: Abnorme Bedingungen sollen
sich nicht zu anderen Modulen ausbreiten können. Kein „unberechtigter“ Zugriff
auf Daten (keine globalen Variablen).
5.3 Fünf
Prinzipien zur Modularität
-
Linguistische Module: Module sollen zu
syntaktischen Einheiten der benutzten Sprache korrespondieren.
-
-
Wenig Schnittstellen: Jedes Modul sollte mit
möglichst wenig anderen Modulen kommunizieren.
-
-
Kleine Schnittstellen: Wenn 2 Module
kommunizieren, dann sollten sie so wenig Informationen wie möglich austauschen.
-
-
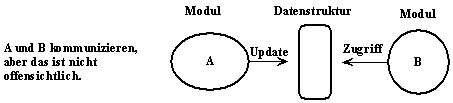
Explizite Schnittstellen: Wenn 2 Module
kommunizieren, dann sollte dies aus dem Text von einem oder beiden Modulen
hervorgehen.
-

Information hiding: Alle Informationen eines
Moduls sollten privat sein, außer sie ist explizit als öffentlich deklariert.
Ein
Modul sollte einerseits offen für Erweiterungen sein, andererseits geschlossen,
damit es andere benutzen können.
è Vererbung
5.4 Objektorienierter Entwurf:
Def. 1: Objektorientierter Entwurf ist eine Methode,
die zu Software-Architekturen führt, die auf den vom System zu manipulierenden
Objekten basiert (anstatt auf den Funktionen, die das System bereitstellt).
Motto: Frage nicht als erstes, was das System tut; frage,
was es wem tut!
Erwarteteter Vorteil:
-
Erweiterbarkeit, da die Funktionen eines Systems sich viel leichter
verändern als die Daten.
-
Wiederverwendbarkeit, da die Funktionen weit spezifischer sind als die
Daten.
Bsp.:
Buchhaltungsprogramm
Aufgaben:
1.
Wie findet man die Objekte?
2.
Wie beschreibt man die Objekte?
3.
Wie beschreibt man Beziehungen zwischen den Objekten?
Ad 1: Objekte sind meist vorgegeben, da Programme Aspekte
der Welt abbilden sollen, die natürlicherweise aus Objekten aufgebaut sind.
Beispiel:
Simulation
Ad 2: Objekte werden als abstrakte Datentypen
beschrieben:
1.
Objekte werden in Objektklassen beschrieben.
2.
Objektklassen durch ihre Implementierung zu beschreiben, führt zur
Überspezifikation. Daher werden nur ihre Operationen (Dienste) einschl. ihrer
formalen Eigenschaften angegeben (abstrakter Datentyp).
3.
Als Spezifikationsssprache eignen sich Klassendiagramme in UML.
Ad 3: Als Spezifikationsssprache eignen sich dynamische
Konstrukte in UML.
Def. 2.: Objektorienierter Entwurf ist die Konstruktion
von Software-Systemen als strukturierte Sammlungen von Implementierungen
abstrakter Datentypen.
Die
Strukturiertheit drückt sich in 2 Typen von Beziehungen zwischen Objektklassen
aus:
Kunde
(client) und Erbe (descendant):
-
Eine Klasse ist Kunde einer anderen Klasse, wenn sie dessen Dienste
(Operationen) in Anspruch nimmt.
-
Eine Klasse ist Erbe einer (oder mehrerer) anderen Klasse, wenn sie als
Erweiterung oder Spezialisierung dieser entworfen ist.
5.5 Kennzeichen
von Objekt-Orientiertheit
Ebene1 – Objektbasierte
modulare Struktur:
Systeme
sind modularisiert auf der Basis ihrer Datenstrukturen.
Ebene2 – Datenabstraktion:
Objekte
sollen als Implementierungen abstrakter Datentypen
beschrieben
werden.
Ebene3 – Automatische
Speicherverwaltung:
Nicht mehr gebrauchte
Objekte sollten von der zugrundeliegenden Programmiersprache ohne Intervention
des Programmierers aufgeräumt (d.h. ihr Speicherplatz freigegeben) werden .
Ebene4 – Klassen:
Jeder nicht-triviale Typ ist
ein Modul und jedes komplexe Modul ist ein Typ (Module können wie Typen
abgefragt werden).
Ebene5 – Vererbung:
Eine Klasse kann als
Erweiterung oder Beschränkung einer anderen Klasse definiert werden.
Ebene6 – Polymorphismus und
dynamisches Binden:
Programmeinheiten sollten zu
Objekten von mehr als einer Klasse referieren und Operationen sollten
verschiedene Realisierungen in verschiedenen Klassen haben.
Ebene7 – Mehrfache und
wiederholte Vererbung:
Es sollte möglich sein, eine
Klasse als Erbe von mehr als einer Klasse und auch mehrfach zu derselben Klasse
zu definieren.
6.
Objektorientierte Analyse
UML: Basiskonzepte
UML: Statische Konzepte
UML: Dynamische Konzepte
7.
Benutzungsoberflächen
8.
Objektorientierter Entwurf
9.
Entwurfsmuster
10. Datenbanken
s.
Power-Point Folien von Heide Balzert.
10
s. auch unten.
11. Programmieren im Internet
11.1. HTML = Hypertext Markup Language
Ziel: Hypermedia-Sprache fuer das WWW (Texte, Bilder, Töne, Verweise, Interaktionen)
Methode: Rohdaten werden mit Zusatzinformationen (Tags) versehen, die von einem WWW-Browser beim Client interpretiert werden. Tags können geschachtelt und durch Attribute parametriert werden
<tagname attribut="Value"> angezeigter Text </closingtag>
Ein einfaches
Beispiel:
<html>
<head>
<title>Html-Beispiel</title>
</head>
<body>
Dies ist ein Html-Text
<p><b>Eine fette Überschrift.</b>
<p><a href="http://ki.informatik.uni-wuerzburg.de/">Ein Verweis</a>
<p>Ein Bild<img SRC="Weihnachtsmann.jpg" NOSAVE height=338 width=474>
</body>
</html>
Die wichtigsten Html-Befehle:
Grundgerüst:
<html>
<Head>
<Title> Titelzeile des Dokumentes </Title>
</Head>
<Body>
Eigentlicher Inhalt des Dokumentes
</Body>
</html>
Titelzeile erscheint nicht im Dokument selbst, sondern meist in der Titelzeile des WWW-Browsers und wird von Suchmaschinen ausgewertet.
Wichtige textbasierte Tags:
Überschriften
(headings):
<H1> Überschrift1 </H1> ...
<H6> Überschrift6 </H6>
Abschnitte
(paragraphs):
<p> Abschnitt </p>
Hervorhebungen
(formatting):
<b> fetter Text (bold) </b>
<i> kursiver Text (italic) </i>
<u> unterstrichener Text (underline) </u>
<font size = „+/- x“ vergrößerter/verkleinerter Text </font>
<HR> Horizontale Linie (kein Abschlußbefehl)
<BR> Zeilenumbruch (Break) (kein Abschlußbefehl)
Aufzählungen:
<UL> unordered lists bzw. <OL> ordered lists
<LI> Listenelement (list item) ...
<LI> Listenelement
</UL> bzw.</OL>
Hyperlinks einbinden
(anchor):
<a href = „URL“> Bezeichnung des Hyperlinks oder lokaler Datei </a>
Bild einbinden
(image):
<img Align = Top oder Middle oder Bottom SRC = „URL“
Hyperlink und Bild kann auch kombiniert werden, wenn statt der Bezeichnung des
Links ein Bild angegeben wird.
Tabelle: dient oft zur einheitlichen Ausrichtung von Texten in mehreren Spalten.
Tabellen <Table> werden zeilen- <tr> bzw
<th> und kästchenweise <td> beschrieben.
Formulare:
<FORM METHOD=POST oder GET ACTION="URL des Bearbeitungsprogramms">
Inhalt
</form>
Methode GET hängt die Eingabedaten an die URL an (Längenbeschränkung, nur praktikabel bei wenigen Eingaben), POST erzeugt einen eigenen Datenstrom.
Eingabe-Tags innerhalb eines Formulars: INPUT, SELECT und TEXTAREA.
<INPUT ...Attribute ...>
Attribut TYPE="....", z.B.
CHECKBOX, HIDDEN, PASSWORD, RADIO, RESET, SUBMIT, TEXT, IMAGE.
Attribut NAME="...."
Name des Eingabefeldes. Dieser Name wird im Datenstrom zurückgegeben.
Attribut VALUE="...."
Defaultwert (TEXT, HIDDEN), Wert des Menüpunkts (CHECKBOX, RADIO), Beschriftung des Feldes (RESET, SUBMIT).
Beispiele:
Beispiel 1: Eingabezeile von 40 Zeichen Länge:
<INPUT TYPE="text" NAME="name" SIZE=40 VALUE="No Name">
Beispiel 2: Drei Radio-Buttons, Knopf 1 ist gedrückt:
<INPUT TYPE="radio" NAME="rb1" VALUE="1" CHECKED>Knopf 1
<INPUT TYPE="radio" NAME="rb1" VALUE="2">Knopf 2
<INPUT TYPE="radio" NAME="rb1" VALUE="3">Knopf 3
<TEXTAREA> .... </TEXTAREA>
erlaubt die Definition eines rechteckigen Eingabefeldes mit Attributen Rows and Cols und einem Defaulttext.
NAME="...." Name des Eingabefeldes (wie bei INPUT).
ROWS="...." Anzahl Zeilen des Feldes
COLS="...." Anzahl Spalten des Eingabefeldes
Beispiel:
<TEXTAREA NAME="name" ROWS=5 COLS=40> Beliebiger Text, der im Textfeld steht. </TEXTAREA>
<SELECT> .... </SELECT>
Selektionsfelder gleichen Pull-Down-Menüs. Attribute
NAME="...." Name des Feldes
SIZE="...." Anzahl der dargestellten Elemente.
MULTIPLE Erlaubt Mehrfachauswahlen.
Ein Menüfeld wird über das OPTION-Tag beschrieben, wobei der voreingestellte Menüpunkt über das SELECTED-Attribut ausgewählt wird und das Value-Attribut den Rückgabewert angibt.
Beispiel:
<SELECT NAME="name">
<OPTION Value=1 SELECTED>Text1
<OPTION Value=2>Text2
<OPTION Value=3>Text3
</SELECT>
Integriertes
Beispiel zu Formularen:
<html>
<head> <title>Formularbeispiel</title> </head>
<body>
<form method="POST" action="justdoit.asp"
name="justdoit.asp">
<p>Ihr Name: <input type="text" name="name" size="20"></p>
<p>Ihre Adresse:</p>
<p><textarea rows="2" name="adresse"
cols="34"></textarea></p>
<p>Gewünschte Lage: <select size="1" name="Gebiet">
<option
value="city">Citylage</option>
<option
value="stadt">Stadtgebiet</option>
<option
value="aussen">Außenbezirk</option>
</select></p>
<p>Kategorie
<input type="radio" value="1stern" name="kat">*
<input type="radio" value="2stern" name="kat" checked>**
<input
type="radio" value="3stern"
name="kat">***
<input type="radio" value="4stern" name="kat">****</p>
<p>Ausstattung:
<input type="checkbox" name="ausst" value="WC">WC
<input type="checkbox" name="ausst" value="Dusche">Dusche
<input
type="checkbox" name="ausst"
value="Bad">Bad
<input type="checkbox" name="ausst" value="Fernseher">Fernseher
</p>
<p>Preislage:</p>
<p><select size="1" name="preis">
<option
value="billig">30-70</option>
<option
value="einfach">70-100</option>
<option
value="gut">100-150</option>
<option
value="teuer">über 150</option>
</select></p>
<p>
<input type="submit" value="Abschicken" name="B1">
<input type="reset" value="Zurücksetzen"
name="B2">
</p>
</form>
</body>
11.2 XML – Extensible Markup Language
Motivation:
- praktisch unbegrenzter Bedarf an anwendungsspezifischen Tags
- Ermöglichung der Weiterverarbeitung der Daten erfordert Semantik
Lösung: Einfache Sprache zur Definition von neuen Tags: XML (Vereinfachung von SGML)
Beispiel:
Bank will Börsenkurse für ihre Kunden aufbereiten und als Html-Tabellen darstellen.
Problem: Bei den Zahlen ist nicht vermerkt, was sie bedeuten, z.B. welches der heutige
Börsenkurs ist. Erforderlich waere z.B. ein Tag <Kurs Datum = heute> zur Markierung aktueller Kurse – kein Bestandteil von html.
Konsequenz: Eine XML-Datei ist nur in Verbindung mit einer DTD (Document Type Definition) interpretierbar.
Struktur der Tags in XML ähnlich wie in Html, allerdings muß zu jedem Anfangstag auch ein Endetag existieren (Abkürzung z.B. <hr/> statt <hr> </hr>).
Definition einer DTD:
Die Grammatik besteht aus Elementen, die Terminale (Tags und ihre Attribute) und Nichtterminale (zusammengesetzte Elemente) definieren.
Formulierung der Regeln für Nichtterminale (a, b seien Elemente):
- Gruppierung: (a b)
- Alternative: a | b
- Sequenz: a , b
- Wiederholung 0 .. n : a *
- Wiederholung 1 .. n: a +
- Wiederholung 0 .. 1: a ?
Formulierung der Terminale:
Elemente: <!element „elementname“ „typ“>
Attributlisten: <!attlist „elementname“ („attributname“ „typ“ #implied | #required)+
Entitäten: <!entity „name“ „“kürzel““>
Beispiel für eine DTD:
<?xml version = „1.0“ encoding= „UTF-8“?>
<!ELEMENT adressbuch anschrift*>
<!ELEMENT anschrift (name, (strasse | postfach)?, ort)>
<!ELEMENT name ANY>
<!ELEMENT strasse ANY>
<!ELEMENT ort EMPTY>
<!ATTLIST ort
plz CDATA #REQUIRED
name CDATA #REQUIRED
land CDATA #IMPLIED>
Beispiel für ein zugehöriges Dokument:
<?xml version=“1.0“?>
<!doctype adressbuch SYSTEM „anschrift.dtd“>
<adressbuch>
<anschrift>
<name> Dietmar Seipel </name>
<strasse> Am Hubland </strasse>
<ort plz=“97074“ name=“Wuerzburg“/>
</anschrift>
</adressbuch>
Verweise:
XLink: Links können mit semantischen Informationen angereichtert werden.
Xpointer (XML Pointer Language): Relative Indexierung von Zielstellen eines Links
Bsp.: id(Ziel).following(1,#element) Keine Def. eines Verweisziels notwendig.
Vergleich mit HTML: 1. Definition eines Verweiszieles: <a name = „Ziel“>
2. Adressierung: dokument.html#ziel
12. Regelinterpreter
Eine Regel besteht aus einer Vorbedingung (wenn...) und einer Aktion (dann...). Die Vorbedingung beschreibt eine Situation, in der die Aktion ausgeführt werden soll. Es gibt 2 Typen von Aktionen:
- Implikationen oder Deduktionen, mit denen der Wahrheitsgehalt einer Feststellung hergeleitet wird, z.B.
Wenn Nackensteife & hohes Fieber & Bewußtseinstrübung
dann Verdacht auf Meningitis.
- Handlungen, mit denen ein Zustand verändert wird.
z.B. Absetzen (a, b) {a, b sind Klötzchen}
wenn frei (a) & im_Greifarm (b)
dann auf (a, b) & frei (b) & im_Greifarm ()
Ein regelbasiertes System besteht aus
1. einer Datenbasis, die die gültigen Fakten enthält,
2. den Regeln zur Herleitung neuer Fakten und
3. dem Regelinterpreter zur Steuerung des Herleitungsprozesses.
Die beiden wichtigsten Regelinterpreter-Typen sind:
- Vorwärtsverkettung (Forward Reasoning): Ausgehend von der Datenbasis wird aus den Regeln, deren Vorbedingungen erfüllt sind, eine ausgewählt, ihre Aktion ausgführt (die Regel „feuert“) und damit die Datenbasis geändert. Dieser Prozeß wird solange wiederholt, bis keine Regel mehr feuern kann.
1. DATEN <- Ausgangsdatenbasis
2. Solange DATEN erfüllt Terminierungskriterium oder keine Regel anwendbar tue
2.1 Wähle Regel R, mit R.Vorbedingung (DATEN) = True
2.2 DATEN <- R.Aktion (DATEN)
Die Auswahl einer Regel erfolgt in zwei Schritten:
1. Vorauswahl: Bestimmung der Menge aller ausführbaren Regeln („Konfliktmenge“)
2. Auswahl: Auswahl einer Regel mit „Konfliktlösungsstrategie“ (z.B. erste Regel, speziellste Regel, aktuellste Regel, Regel mit höchster Priorität).
- Rückwärtsverkettung (Backward Reasoning): Ausgehend von einem Ziel werden nur die Regeln überprüft, deren Aktionsteil das Ziel enthält. Falls Parameter der Vorbedingung unbekannt sind, werden sie mit anderen Regeln hergeleitet oder vom Benutzer erfragt.
Die Komplexität der Regelvorbedingung bestimmt die Ausdrucksstärke und Effizienz eines Regelinterpreters. Wichtige Typen sind:
- Nachschauen in der Datenbasis (z.B. ist Bauklotz1 rot ?)
- Nachschauen in der Datenbasis und Rechnen (z.B. ist Bauklotz1 > Bauklotz2 ?)
- Pattern Matching (und Rechnen): (z.B. finde größten Bauklotz auf dem Tisch ?)
- Unifikation: (z.B. f(g(x),a) = f(g(a),x) )
Beispiele für Regelinterpreter:
1. Einfach: vorwärtsverkettet, Nachschauen in der Datenbasis.
Regelsyntax:
<Regel> ::= <Vorbedingung> <Aktion>
<Vorbedingung> ::= (<paedikat> <objekt> <wert>)+
<Aktion> ::= <operator> <objekt> <wert>
<praedikat> ::= „=“
<operator> ::= „add“
Darstellung der Fakten: Hashtabelle mit Einträge <objekt> <wert>
2. Prolog: rückwärtsverkettet, Unifikation.
Umzugsregeln:
Wie voll ist das Büro?
o sehr voll -> Büro zu klein (40 = p5)
o normal
o unterbelegt -> Büro zu klein (-40 = n5)
Gab es Neueinstellungen?
o viele -> Büro zu klein (80 = p6)
o wenige -> Büro zu klein (20 = p4)
o keine -> Büro zu klein (-20 = n4)
Sind Arbeitnehmer ausgeschieden?
durch Kündigung ->
Büro zu klein (-20 = n4)
durch Pensionierung ->
Büro zu klein (-20 = n4)
durch freiwilliges Ausscheiden ->
Büro zu klein (-20 = n4)
Wenn Büro zu klein = etabliert
Dann Umzug (40 = p5)
Nur wenn Büro zu
klein:
Ist genug Geld für Umzug da?
ja -> Umzug (40 = p5)
vielleicht
nein -> Umzug (-40 = n5)
Diagnose ist etabliert, wenn sie mindestens 42 Punkte hat.
13. Beispiel: Diagnostisches Problemlösen
Auswahl von Problemlösungen aus vorgegebener Menge:
Einfacher Basisalgorithmus:
Eingabe: Antworten auf Fragen
Ausgabe: Diagnosen
Wissen:
1. Liste von Fragen mit Antwortalternativen
2. Menge von Diagnosen
3. Regeln, die Fragen und Diagnosen verknüpfen, der Art
Wenn <Bedingung> dann bewerte <Diagnose> mit <Evidenz>
bzw. wenn <Bedingung> dann stelle <Frage>
wobei <Bedingung> eine
(zunächst einstellige) logische Verknüpfung über Fragen bzw. Diagnosen ist.
Algorithmus:
1. Für alle Fragen aus Frageliste tue:
1.1 Stelle Frage und überprüfe Antwort
1.2 Führe Aktionen aller Regeln aus, deren <Bedingung> jetzt erfüllt ist.
1.2.1 Aktualisiere Frageliste
1.2.2 Aktualisiere Diagnosebewertungen. Falls sich Diagnosestatus ändert,
1.2.2.1 aktualisiere Diagnoseliste
1.2.2.2 überprüfe Diagnoseregeln
2. Gib die Diagnoseliste als Ergebnis aus.
Modellierung:
Beteiligte Objektklassen:
n Wissensbasis
n Fall
n Objekt
n Diagnose
n Frage
n Fragen-OC
n Fragen-MC
n Antwort
Problem: Wie werden Evidenzen verrechnet?
Lösung: Internist-Schema: Kategorien, die in Punktzahlen umgesetzt werden. Verrechnung durch Addition
Alternative: Verrechnen von Wahrscheinlichkeiten.
Problem: Wann gilt eine Diagnose als bestätigt?
Lösung: Einführung eines Schwellwertes. Aus bestätigten Diagnosen können Schlußfolgerungen mit Regeln gezogen werden.
Alternative: Die Wahrscheinlichkeiten werden weiterpropagiert.
Problem: Wie kann man effizient Regeln Überprüfen?
Lösung: Indiziere die Regeln von den Objekten in der Vorbedingung aus
Spezialfall: Bei einstelligen Regeln kann man die Regeln als attributierte Assoziationen (Verweislisten) der Objekte repräsentieren, z.B. Wenn x dann y mit Bewertung z:
Setze bei einem Attribut von x einen Verweis auf y mit dem Attribut z.
Problem: Wie kann man Schlußfolgerungen begründen?
Lösung: Indiziere die Regeln von den Objekten der Aktion aus und notiere bei jeder Regel, ob sie gefeuert hat.
Alternative: Notiere bei jedem hergeleitetem Objekt alle benutzen Regeln.
<Aktivitätsdiagram, Klassendiagramm, Programmcode>
zu 10. Relationale
Datenbanken (s. auch PP-Folien)
Idee: Organisation von Daten in
2-dimensionalen Tabellen (Relationen)
Themen: 1. Organisation der Relationen:
Redundanzfreiheit, Schlüssel, Indexstrukturen
2. Abfragen als
Datenstrom-Operatoren
Beispiel-Relationen
Relation
"Kurs-Punkte"
Kurs Matrikel %Punkte
PI1 123456 55
PI1 567890 70
PI2 123456 49
PI2 222222 80
PI1 333333 65
THI 567890 72
Relation
"Adresse"
Matrikel Name PLZ Straße Tel.
123456 A.
Schneider 97218 Hauptstr. 1 704426
567890 B.
Müller 97070 Sanderstr. 2 463244
222222 C.
Maier 97070 Juliuspromenade 4 323232
Relation
"Kursvoraussetzung"
Kurs Voraussetzung
PI2 PP
SWP PI2
SWP PI1
SWP PP
Relation
"Kurs-Zeiten"
Kurs Tag Stunde
PI2 Mo 10:00
PI2 Do 10:00
PI2 Fr 10:00
TI1 Mo 13:30
TI1 Mi 13:30
Relation
"Kurs-Raum"
Kurs Raum
PI2 HS2
TI1 HS2
Spalten-Namen:
Attribute (z.B. Kurs, Matrikel-Nr, ...)
Zeilen:
Tupel (Inhalt der Relation)
Restriktionen:
-
Keine 2 Zeilen dürfen
identisch sein.
-
Ein Attributwerte
(d.h. Einträge in einem Tupel) müssen elementar sein.
Eine
Datenbank ist eine Menge von Relationen. Deren Aufteilung ist eine Frage des
Designs. Dabei sollen die Grundsätze der Eindeutigkeit und Redundanzfreiheit
beachtet werden.
Bsp.:
Angaben zu Kursen und Studenten in einer Relation:
Matrikel Name
PLZ Straße Tel
Kurs Voraussetzung Tag
Stunde Raum %Punkte
è
hochgradig redundant
Bsp mit 2
Relationen
(Kurs Tag)
+ (Kurs Stunde)
è
nicht eindeutig
redundanzfreies,
eindeutiges Design (unter bestimmten Annahmen) mit 5 Relationen:
(Kurs
Matrikel %Punkte)
(Matrikel
Name PLZ Straße Tel)
(Kurs
Voraussetzung)
(Kurs Tag
Stunde)
(Kurs Raum)
Schlüssel (key)
Schlüssel
dienen dazu, Tupel in einer Relation eindeutig, aber möglichst knapp zu
charakterisieren.
Bsp.:
Matrikel-Adress-Relation: Key sei Matrikel. Dann können nicht zwei Adressen für
einen Studenten gespeichert werden.
<weitere
Beispiele durchgehen>
Man kann
eine Relation als Abbildung vom Schlüssel zu den übrigen Attributen betrachten.
Speicher-Strukturen
für Relationen
Kriterien:
Die Operationen Einfügen, Löschen, Suchen sollen möglichst effizient sein.
Sortierung
entsprechend den häufigsten zu erwartenden Anfragen.
Mögliche
Strukturen:
1.
Binärer Suchbaum
2.
Array, der nach den
Suchkriterien indiziert ist
3.
Hash-Tabelle
Primärer Index:
Suchkriterium nach dem die Daten physikalisch abgespeichert sind.
(hat
wahrscheinlich den grössten Einfluss, wie schnell typische Fragen beantwortet
werden).
Sekundäre Indices:
Zusätzliche Suchkriterien (Attribute).
Kandidat
für primären Index: Schlüssel
Realisierung
von sekundären Indices: Anlegung
separater Suchstrukturen (meist Hashtabellen) mit Zeiger auf Einträge des
primären Index.
Anfragen
Welche
%Punkte erreichte der Student mit Matrikel 123456 in PI1?
PI1 123456
|
Kurs |
Matrikel |
%Punkte |
?
Suchstrategie:
Suche
alle Tupel mit Matrikel 123456, und prüfe Kurs = PI1, dann gib Punkte aus.
Aufwand:
ohne Indices: O(n); mit Indices O(1)
bzw. O(log n)
Index
über einem Attribut, danach ggf. lineare Suche!
Welche
%Punkte erreichte A.Schneider in PI1?
A. Schneider
|
Matrikel |
Name |
PLZ |
Straße |
Tel |
|
-------------------------------------
PI1 |
|
Kurs |
Matrikel |
%Punkte |
?
Suche
alle Tupel in Adress-Relation mit Name = A.Schneider und suche mit deren
Matrikel weiter in Kurs-Punkte-Relation, ob Kurs = PI1, dann gibt %Punkte aus.
Aufwand:
ohne Indices O(n + km); mit Indices O(k)
n
= #Tupel Adress-Relation, m = #Tupel Kurs-Punkte-Relation, k = #Übergabewerte
Wo ist
A.Schneider am Fr. um 10:00?
A. Schneider
|
Matrikel |
Name |
PLZ |
Straße |
Tel |
|
-------------------------------------
|
|
Kurs |
Matrikel |
%Punkte |
|
| Fr 10:00
|
Kurs |
Tag |
Stunde |
|
|
|
Kurs |
Raum |
?
Aufwand: ohne
Indices: Aufwand bestenfalls proportional zur Summe der Einträge der 4
Relationen, bedeutend höher bei Mehrfachauftreten von Übergabewerten.
Mit
Indices: Nur abhängig vom Mehrfachauftreten von Übergabewerten.
Algebra auf
Relationen
Alle
Operationen können als Filter verstanden werden, die nur bestimmte Tupel oder
Attribute (eigentlich Abbildung) durchlassen. Jede Operation liefert eine
Relation als Ergebnis.
1.
Selektion
(s)
(Auswahl von Tupeln aus einer Relation)
Bsp.: sKurs = PI1
(Kurs-Punkte) :
|
Kurs |
Matrikel |
%Punkte |
|
PI1 |
123456 |
55 |
|
PI1 |
567890 |
70 |
|
PI1 |
333333 |
65 |
2.
Projektion
(p)
(Auswahl von Attributen aus einer Relation)
Bsp.: p Matrikel (sKurs
= PI1
(Kurs-Punkte))
|
Matrikel |
|
123456 |
|
567890 |
|
333333 |
3. Mengen-Operationen: Auswahl von Tupeln aus dem Kreuzprodukt
zweier Relationen
Vereinigung
R È S
Durchschnitt
R Ç S
Mengen-Differenz R – S
Bsp:
|
R: |
|
S: |
|
R È S |
|
R Ç S |
|
R – S |
|
|
A |
B |
A |
B |
A |
B |
A |
B |
A |
B |
|
0 |
1 |
0 |
1 |
0 |
1 |
0 |
1 |
2 |
3 |
|
2 |
3 |
4 |
5 |
2 |
3 |
|
|
|
|
|
|
|
|
|
4 |
5 |
|
|
|
|
Achtung: Doppelte Einträge werden
eliminiert.
4.
Verbund |x| (Join; Auswahl von Tupeln aus dem Kreuzprodukt
zweier Relationen, die bestimmte Eigenschaften gemeinsam haben)
Bsp.: Kursraum |x| Kurszeiten:
Kurs = Kurs
|
Kurs |
Tag |
Stunde |
Hörsaal |
|
PI2 |
Mo |
10:00 |
HS2 |
|
PI2 |
Do |
10:00 |
HS2 |
|
PI2 |
Fr |
10:00 |
HS2 |
|
TI1 |
Mo |
13:30 |
HS2 |
|
TI1 |
Mi |
13:30 |
HS2 |
4a) Natürlicher Verbund: vereinfachte
Schreibweise für Join, falls das einzige vereinigte Attribut gleichen Namen.
Bsp.: Kursraum |x| Kurszeiten
Zusammengesetzte Anfragen:
Kursbelegung des HS2?
p Tag, Stunde (sRaum = HS2 (Kurs-Raum |x| Kurs-Zeiten))
SQL: Standard Query Language für
relationaler Datenbanken
Select -> Projektierte Attribute
From ->
Beteiligte Relationen
Where ->
Bedingungen (z.B. für Selektion, Join)
Bsp.:
p Tag, Stunde (sRaum = HS2 (Kurs-Raum |x| Kurs-Zeiten)) wird zu:
Select Tag, Stunde
From Kurs-Raum,
Kurs-Zeiten
Where Kurs-Raum.Kurs = Kurs-Zeiten.Kurs AND Raum
= HS1
Implementierung
relationaler Operationen
1. Implementierung der Mengenoperationen
a) ohne Index: Sortieren und Mischen: 0(n log n) + 0(n) = O (n
log n)
b) mit Index: O(n)
(S habe Index; Vereinigung)
1. Füge alle Tupel von S der Ergebnis-Relation hinzu
2. Für alle Tupel von R: Prüfe mittels Index, ob das Tupel
auch in S vorkommt; falls nein, füge es hinzu.
2. Implementierung der Projektion:
Alle Tupel durchlaufen und eine Kopie
ohne die ausgefilterten Attribute anlegen (Index nützt nichts): Aufwand: O(n)
Problem: Duplikate.
Lösung1: Sortieren O(n log n) und
dann Duplikate eliminieren O(n) = O(n log n)
Lösung2: Beim Anlegen der Kopien eine
Hash-Tabelle aufbauen, um doppelte Belegungen sofort zu erkennen: O(n)
3. Implementierung der Selektion:
a) ohne Index: alle Tupel überprüfen. Aufwand O(n)
b) mit Index: einfachster Fall: Selektionskriterium ein
Attribut A=a: O(1)
komplexerer Fall:
Selektionskriterium mehrere Attribute A=a AND B=b
Aufwand
proportional der Einträge beim zuerst gesuchten Attribut.
4. Implementierung des Verbunds
(Natural Join)
Relation R sei A|B mit r Tupeln und
Relation S sei B|C mit s Tupeln
a) Nested-loop-Join
Für alle Tupel r in R tue
Für alle Tupel s in S tue
Wenn r und s im Attribut B übereinstimmen
Dann füge Tupel mit Attributen A|B|C zu Ergebnisrelation hinzu
Aufwand:
O(r * s)
b)
Sort-Join
1. Mische Tupel von R und S mit Attribut B vorne und einem
zusätzlichen Attribut, das anzeigt, woher das Tupel kommt (von R bzw. von S)
z.B. (a, b) von R wird zu (b a R)
2. Sortiere die Tupel nach ihrem B-Wert -> Alle Tupel mit
gleichem B-Wert erscheinen untereinander.
3. Füge bei Tupeln mit gleichem B-Wert jede Kombination von R
mit jeder von S der Ergebnisrelation hinzu.
Aufwand:
1. Mischen: O(r + s)
2. Sortieren: O((r+s) log
(r+s))
3. Ausgabe: O(m) m
= # Ergebnistupel
Gesamt: O(m + ((r+s) log (r+s)) da m > r+s sein kann
c) Index-Join
Wenn R einen Index auf Attribut B hat,
werden alle Tupel von S durchlaufen und nach ihrem Wert unter B bei dem Index
von R nachgeschaut.
Aufwand:
Durchlaufen von S: O(s)
Durchlaufen+Nachschauen bei R: O(s+m)
Algebraische Umformungsgesetze für Relationen
Motivation: Selektionen und Projektionen
möglichst früh anwenden, da die Tupel- bzw. Spaltenanzahl reduziert wird.
Wo ist A.Schneider am Do. um 10:00?
p Raum (sName =
A.Schneider AND Tag = Do AND Stunde = 10:00
(Kurs-Raum |x| (Kurs-Zeiten |x|
(Kurs-Punkte |x| Kurs-Adresse))))
versus
p Raum (Kurs-Raum
|x| ((sTag = Do AND Stunde = 10:00 Kurs-Zeiten)
|x| (Kurs-Punkte |x| (sName = A.Schneider Kurs-Adresse))))
Die zweite Formulierung ist
wesentlich effizienter, da die Relationen an der frühest möglichen Stelle
verkleinert werden. Automatische Optimierung wünschenswert!
Problem: Welche Umformungsregeln sind
erlaubt?
Selektion:
1. Selektion Pushing: sC (R |x| S) = (sC R) |x| S, falls alle
Attribute von Bedingung C in R vorkommen
2. Selektion Splitting: sC AND D R = sC (sD R).
Idee: sC und sD in verschiedene
Relationen pushen.
3. Kommutativität: sC (sD R) = sD (sC R)
Projektion:
Projektion
Pushing: pL (R |x| S) = pL (pM R |x| pN S)
A=B A=B
mit M = Alle Attribute von L, die in
R sind einschl. A (falls nicht ohnehin in L)
mit N = Alle Attribute von L, die in
S sind einschl. B (falls nicht ohnehin in L)
Projektion Pushing bei
Mengenoperationen funktioniert nur bei Vereinigung, nicht für Durchschnitt und
Differenz.
pL (R È S) = pL R È pL S aber:
pL (R Ç S) ¹ pL
R
Ç pL S
Gegenbeispiel: R = {A, B} mit Tupel
(a, b); S = {A, B} mit Tupel (a,c)
pA (R Ç S) = ()
pA R Ç pA S = (a)
Für Vereinigung und Durchschnitt
gelten: Kommutativität, Assoziativität und Distributivität
Für Join: Kommutativität, aber nicht
Assoziativität.
Gegenbeispiel: R = {A, B}, S = {B,
C}, T = {A, D}
(R |x| S) |x| T ¹ R |x|
(S |x| T)